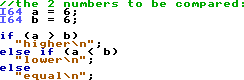NO SANE PERSON ENCODES X86 ASSEMBLY INSTRUCTIONS! DO IT NOW IF YOU ARE TIRED OF BEING SANE!
Intro (puters)
x86_64, sometimes called amd64, x64, or Intel 64, is a CPU instruction set found in most consumer PCs. If you're reading
this on an *actual* PC, not a phone, and it was made in the past like 10 years or so, it's probably x86_64. If it's older,
it might be x86, which is the 32-bit predecessor of x86_64. x86 and x86_64 are pretty close. An x86_64 CPU can run
32-bit x86 code, but not vice versa. x86 was the 32-bit extension of the 16-bit Intel 8086 or something that came
out in like the 1970s. Idk. x86_64 has a lot of legacy stuff since it's still backwards-compatible a really long way.
Neat
"Machine code" refers to the code that the CPU actually runs, the individual 1s and 0s at the very lowest level.
While it's not practical nor very useful for most people to program at such a level (unless you're writing an assembler,
compiler, OS (maybe), or just wanna know more about your puter), it's FUN and has good novelty value. Most people are very,
very, very far removed from it. Oh well. This page is about encoding x86_64 instructions (and x86 and maybe even
the 16-bit versions, by extension); going from assembly statements to the 1s and 0s that the CPU runs. If you don't know
assembly, you should learn it.
I do not like the cia
Kinda useless background
I'll assume you know what electricity is: that force of, like, opposing electrical charges or something. I dunno.
Anyways, conductors conduct electricity through them while insulators don't really conduct electricity. Metals are
usually good conductors, and rubber and plastic are usually good insulators. Power cables are just usually a thick metal
wire surrounded by some rubber. One day, though, people found out that the element silicon is weird with electricity.
Sometimes it conducts electricity, but other times it doesn't. They called it a semiconductor. And thus mankind devolved.
They discovered that you can use these semiconductors to make logic gates: litle circuits that take separate electrical
signals as input, and whether or not they output an electical signal is dependent on the inputs. Like, an AND gate would
output a signal if both of its inputs have a signal. There's also some stuff about analog vs digital: in analog,
the 'strength' of the signals might be taken into account, but in digital, every signal is only ON or OFF, and there's
no in between. As numbers, this ON and OFF would come to be known as true and false, or 1s and 0s. Don't forget about 1s and 0s here.
They're really important. For some reason, digital electronics absolutely bodied analog electronics I think. So everything
now is digital.
Those logic gates can get pretty wild. Individually, there's not many more than simple logical gates whose
name and functions are the same as regular words: AND, OR, NOT. There's also XOR, which is important, and NAND,
NOR, and XNOR which are just NOT combined with the previous ones. Ehh let's throw in some truth tables for them.
Truth tables are tables that show the output of a gate for each state of its inputs.
AND truth table
1 AND 1 = 1
0 AND 1 = 0
1 AND 0 = 0
0 AND 0 = 0
OR truth table
1 OR 1 = 1
0 OR 1 = 1
1 OR 0 = 1
0 OR 0 = 0
NOT truth table
NOT 1 = 0
NOT 0 = 1
XOR gate
1 XOR 1 = 0
0 XOR 1 = 1
1 XOR 0 = 1
0 XOR 0 = 0
Don't get all scared and confused by words like XOR or XNOR and them being capitalized and accompanied by a bunch
of philosophical asides about logic. That's what the CIA wants. Just realize that they're EXTREMELY SIMPLE. "what's
a NOT gate? what does logical NOT mean?" It's so simple, people might be confused by it. NOT is true when its input
is false. NOT is false when its input is true. Should I rephrase? NOT true = false; NOT false = true. It's
so simple! Don't be a CIA cattle.
Pretty soon, people realized that they could combine these logic gates to make some crazy stuff that's actually
quite complicated. They made new manufacturing processes that could put tons and tons of logic gates on a little chip.
By putting together logic gates, you can add numbers, represented by 'trues' and 'falses'. You can store your 'trues' or 'falses' in some kind of medium,
and use logic gates to retreive them from wherever. So they got on some crazy shit. Adding, and arithmetic with numbers,
is one of the main functions of a computer's CPU. Storing memory in the form of 1s and 0s sounds a lot like drives or
RAM. And so they made the computer...
All in all, a computer is just a bunch of electronics: integrated circuits all hooked up and working together
thanks to a motherboard, the green plate-looking-thing with all the traces going between various black rectangles
and electrical components. This stuff is called the hardware. It's physical and is comprised of all those
logic gates. Many of those logic gates are in the CPU; those logic gates are responsible for decoding instructions
to it (of course in the form of 1s and 0s), telling it what operation to do, and doing the operation. It's logic
gates all the way down.
These logic gates provided what you could consider a programming language: a language that programs the CPU (programming
as in telling it what to do). But as programs (something that's run (something a CPU "does" I guess?)) got bigger,
people got tired of coding in their CPU's machine code, so they made up assembly. Assembly tries to make it a little
more readable to humans; in a process called assembling, a program called an assembler takes assembly code as input and outputs machine code.
Then programmers got tired of assembly, too, so they invented what were called "high level programming languages", which
were becoming increasingly independent of the CPU, more readable, and more approachable. This spawned C long ago. The
trend continues still today, where people aren't happy with C, so they came up with languages like Python and JavaScript
which are usually so far removed from the actual CPU that it's not even funny anymore.
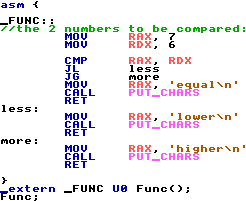
To show what this is like, consider that we want to write a program that compares 2 numbers and prints out either "higher",
"lower", or "equal" depending on the numbers. The only specifics of this program is that the 2 numbers should only be
used once (stored somewhere in memory), and that the output is displayed to the user. I'll show how it might look
in x86_64 assembly, what it'd look like in a higher-level language (HolyC; still low-level compared to what JS frontend
webdevs use), and what it'd look like in a really high-level langauge (Python). Note that "level" in this context just
refers to how far removed something is from the hardware it's ultimately running on.
Even if you don't know much about coding, that should still seem like a lot of code just to compare 2 numbers and tell the user if
the first one is greater, lesser, or equal to the second one. And it is! The last 2 lines are technically HolyC, but
they're only there to actually run the code. This is on TempleOS btw, so I don't have to mess with any linker shit. To
get a glimpse of what it'd look like on Linux or Windows, check out this NASM
tutorial, which is a good tutorial to learn assembly from.
Anyways, next is the same program in HolyC (really similar to C):
It's a lot shorter, isn't it? And not only that, but it's so much more readable. There's variable names, math symbols
to compare the numbers, and not nearly as many crazy strange 2-4 letter phrases. Also note that in both
the above examples, the text in green is a comment and not technically part of the program. It's just cosmetic. In most syntax highlighting,
green means comment. But
if easiness is all you care about, you can do better.
That's in Python. Pretty much the only thing there is to figure out
is that 'elif' just means 'else if'. It's easy. Wanna see it in JavaScript,
the programming language that the front-end of pretty much ALL websites
are coded in? The language that most all client-side ads and trackers are
coded in? The language that has unironically ruined humanity because of how
it's allowed the Internet to run amok and do all the crazy shit it has? The
only language that companies really seem to care about anymore since they
exclusively hire JavaScript front-end webdevs to make their corporate-looking
website have a smooth scrolling function? The THRALL PROGRAMMING LANGUAGE?
It's here. I don't even wanna take a screenshot of it to
give it glory with syntax highlighting. I hate JavaScript and the modern internet.
I'm aware that the internet isn't JavaScript's fault but rather the fault of the companies who are
so enthralled by fucking PR and superficial "sleekness and minimalism" that they
hire spineless JavaScript front-end webdevs to bloat everything up the fuck up just to have a smooth
scrolling transition and shit, but still. (Although I guess that's the fault of the public for
being so thrallish as to be obsessed with superficial shit like the appearance of a website and
wanting it to be fucking SOULLESS).
So all these higher level languages look so much easier and better, right? Well yeah obviously they are easier,
and I'm not saying that assembly is better. But look at all the "things" in the assembly code: RAX, RDX, MOV,
CMP, JL, JG, CALL, and RET. Those make sense to the CPU. (Not the literal text of "RAX" and whatnot, but rather
what they stand for in the machine code after the assembly is assembled). The CPU doesn't really know the word "if",
but it's in most prorgamming languages. Because high-level programming languages don't have to worry about all
that CPU stuff! Well they do; if it's a compiled language like HolyC or C, the compiler needs to in order to compile it
to machine code. But registers, labels, and CPU instructions are *generally* not something you have to think about when
writing code in that language. You sometimes can worry about them if you want, but probably not when the language is interpreted, LOL.
Compiled programming language: the source code is compiled into machine code. Compilation, or compiling, is the act
of turning something into machine code.
Interpreted programming language: the code is executed by a program called an interpreter. Your code
just tells the interpreter what to do, and it's the interpreter that tells the CPU what to do. I guess. This
makes them much slower than compiled languages or machine code, but they're a lot more flexible.
So yeah. The CIA has gotten people so scared of low-level shit. When they code in compiled languages on non-TempleOS
operating systems, linking is so convoluted that they don't know what on earth is happening anymore. They see a
computer BIOS and they think it's a bug. This has distracted them from low-level programming, especially at the
level of CPU instruction encoding. So they stay on superficial front-end web technologies like a bunch of cattle,
where Google implements web environment integrity and
boom there goes your illusion of web browser freedom (such a thing doesn't exist anymore, there's only chromium and the firefox one;
the HTML spec and shit is so complicated that there'll probably never be another web browser, when Google puts whatever
tf they want into chromium, all your "privacy focused" browsers using chromium will probably be forced to choose between using an outdated
chromium (won't let you browse on all the latest and greatest corporate sites since they want the HTML69 CSS cum-margin-double-webkit-animate@thrall property to
make their corporate memphis fade in as you scroll down to look at all their wild claims about their cloud SaaS (the cloud is just someone else's computer))
and incorporating Google features.
Sorry I keep getting sidetracked and cynical about the modern state of computers. I won't do it anymore now. The intro
is over now, so it's time to get what you came here for: X86_64 INSTRUCTION ENCODING. So let's get into it. Starting
now, the site will proceed as though you're an average computer person. You aren't someone's grandma, maybe you have
a bit of coding experience, maybe you booted an OS from a flash drive. Nothing too crazy, but nothing too tame. Feel
free to skip some of the following sections if you already know them.
Binary
I programmed in Lua for years without ever once having to care about binary. Like everyone else, I knew that
computers use binary for numbers, but I never encountered anything where that would actually come into play in
my coding. I was blind in a sense. Imo now, if you program, you should know binary. You'll need it eventually.
Anyways pretty much everything a computer works with is just 1s and 0s, or ONs and OFFs, or trues and falses;
all those terms are interchangeable and called bits. Numbers, then, are obviously represented like that.
The only other information the numbers really have besides the state of the bits
are the "positions" of the bits.
01110010. That's how a computer could represent the number 114. There's 8 different states (represented by digits from 0-1
here: binary), and which ones are on or off is what determines the number it represents. But how can you know the number?
You just have to read it like it's base 2. WHat does that mean? Well the numbers we normally use are in base 10. Each
digit is a 'place' 10 times higher than the last. There's a ones place, a tens place, a hundreds place, etc. Each place/digit
can hold numbers 0-9. After 9, it overflows, adding 1 to the next digit and being set to 0.
Here's counting to 15:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
You should get the pattern. Everyone knows how to count. But how does it relate to base 2? Well it's literally
the same except a digit overflows when it reaches 2.
You see it, right? You can use binary to count to 31 on just 1 hand: having a finger up is a 1, and having a finger
down is a 0. Or if you use 2 hands, you can count to 1023. But how to convert binary to regular decimal (meaning base 10)?
Notice that in binary there's a 1s place, a 2s place, a 4s place, an 8s place, a 16s place, a 32s place, etc. In base 10,
each place is 10x bigger than the last; in base 2, it's 2x bigger than the last. I'm sure you know lots of powers of 2:
1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536, just to name a few. So to convert
from binary to decimal, look at each place starting at the least significant one (the rightmost one here), and if it has a
1 in it, then add the place's value to a total. Now look at the binary number 01001110. Can you convert it yourself? Just
go right to left through the digits/places:
So that's not bad at all. If it doesn't make sense, try this wikihow article.
Too lazy to put much here on how to convert from decimal to binary. It's not as important.
Just take your number and subtract powers of 2 from it: starting at the highest, then descending
down to 1; if it would stay positive, then subtract it and add a 1 into the corresponding place
in the digit, and if it would become negative, skip it and add a 0 into the corresponding place in
the binary digit. Here's converting 78 back into binary:
Converting binary to/from hexadecimal is really important, though. Bitwise operators are too... there's kind of a lot
to go through. I had this other page that's all about binary and goes through a bit of bitwise operators. It's
here. Man, I keep repeating myself.
Binary numbers are prefixed with '0b' in many programming languages, so you can type 78 as '0b01001110'. You
can also that for conversion since the language should let you print out that number in decimal even though
you typed it in binary. Usually in math, a binary number is denoted with a subscript of 2 that comes after it:
010011102. Or to distinguish decimal numbers from binary numbers where there's a chance for confusion
between them (hardly ever, but still), use a subscript of 10: 7810
Hexadecimal
Hexadecimal, sometimes called just 'hex', is a base 16 numbering system. That means that each digit can range
in value from 0-15 unlike base 10's 0-9. But because 10, 11, 12, 13, 14, and 15 can't be written in 1 digit
because of base 10, hexadecimal numbers use A, B, C, D, E, F respectively. So counting from 0 to 19 in hex
looks like this:
0
1
2
3
4
5
6
7
8
9
A (10)
B (11)
C (12)
D (13)
E (14)
F (15)
10 (16)
11 (17)
12 (18)
13 (19)
Which at first seems pretty stupid. It's confusing because sometimes hex numbers look like decimal numbers even when their values
are different. Also it's silly: why does hex even exist? But it's super easy to convert between hex and binary. As long
as you know your hex digits and the binary representations of 0-15, you can do it in your head in not much time at all.
Each group of 4 bits just corresponds to a hex digit! (4 bits is the number you need to represent 0-15, btw). So,
to convert 010011102 to hex:
01001110
chunk, decimal value, hex digit
0100: 4: 4
1110: 14: E
010011102 = 78 = 4E
It's painless once you get the hang of it. I don't think there's much else to say about hex, but so much stuff
involving x86 or anything relativively low level uses it.
In programming languages, hex numbers are usually prefixed with 0x, like 0x4E. Usually it's case-insensitive. In
other places, hex numbers have an 'h' at the end of them, like 4Eh. H isn't a valid hex digit, so there's no ambiguity.
In some other places, though, especially in the documentation of x86_64 stuff, numbers being in hex is implicit,
so make sure you know the number format of what you're reading, because a 20 in hex is very different from a 20 in decimal.
The x86_64 Architecture
Can't really encode x86_64 instructions if you don't know what goes on in x86_64, though. Maybe you could, I dunno,
but it'd be kinda silly. In most (all?) CPUs, there are small areas of memory called registers. They're stored inside
the CPU, so they're *much* faster than RAM. A lot of what a CPU does is just moving data between registers and RAM.
x86 defines 8 32 bit general purpose registers that you can store whatever you want in, although 2 of them are used
for stack stuff, so you probably wouldn't want to. x86_64 increases their size to 64 bits and also adds 8 more 64 bit
general purpose registers. Each of them can store 64 bits of data, usually in the form of a number.
Instructions are the smallest unit of CPU execution. They're... instructions that tell the CPU what to do. For example,
there's an add instruction that can add one register or memory location to another. A "memory location" just means
something stored in RAM. There's a move instruction, usually called mov, that copies data from a register or memory
location to another. And so on. There are lots of different instructions. The easiest way to see these instructions
is through something called assembly language. Assembly language is a programming language composed of statements;
each statement corresponds one-to-one with a machine code instruction. It's specific to each CPU architecture, too,
and maybe the OS depending on what you do with it. This page is dedicated to x86_64 instruction encoding, which means
going from the assembly statements to the machine code that the CPU will directly execute. As such, the specific OS
isn't relevant, except maybe in a few examples of assembly code; if it at all matters, all assembly examples on
this page are in TempleOS/HolyC, and the syntax is similar to regular NASM (using Intel syntax) except:
All mnemonics and register names are capitalized
If a mnemonic can take a variable amount of operands, the number of operands is appended to the mnemonic (eg. IMUL2 vs IMUL3)
There are no sections (like .data, .bss, .text, etc) or anything that might be needed for .ELF files. TempleOS doesn't use .ELF files
If you don't know what any of that means yet, that's ok. They're just differences between TempleOS-style assembly and the style
of assembly that might pop up anywhere else.
Assembly isn't easy at all! Shit. It's a huge pain to try and explain, too, so here's a list of random free x86 assembly tutorials since
I probably won't do a good job (remember that x86 and x86_64 assembly are sort of the same thing; x86_64 is just the 64 bit
extension of x86, blah blah):
Most of my experience with assembly comes from TempleOS and messing around with trying to make a bootloader with NASM.
It seems to be one of those things that just takes time. But it's not too bad once you get it kinda down. Anyways,
if you do any x86_64, you need to know the REGISTERS. As said before, there are 16 general purpose 64 bit registers, and
each of them have 32, 16, and 8 bit subregisters. The 32 and 16 bit subregisters are the least significant bits of the larger
register.
X86_64 Registers
Code
Register name (64 bit)
32 bits
16 bits
high 8 bits*
low 8 bits
000
RAX
EAX
AX
AH (code: 100)
AL
001
RCX
ECX
CX
CH (code: 101)
CL
010
RDX
EDX
DX
DH (code: 110)
DL
011
RBX
EBX
BX
BH (code: 111)
BL
100
RSP
ESP
SP
none
SPL[1]
101
RBP
EBP
BP
none
BPL[1]
110
RSI
ESI
SI
none
SIL[1]
111
RDI
EDI
DI
none
DIL[1]
1.000
R8
R8D
R8W
none
R8B
1.001
R9
R9D
R9W
none
R9B
1.010
R10
R10D
R10W
none
R10B
1.011
R11
R11D
R11W
none
R11B
1.100
R12
R12D
R12W
none
R12B
1.101
R13
R13D
R13W
none
R13B
1.110
R14
R14D
R14W
none
R14B
1.111
R15
R15D
R15W
none
R15B
*: high 8 bits of the 16 bit subregister
[1]: only encoded when REX prefix is present; x86_64 only
Note: for the register code, a 1 before the . means the bit must be set in REX.R, REX.X, or REX.B
Tricky stuff. Note that none of the 64 bit registers are in plain x86. Also, anything talking about
a REX prefix is just info on how it's encoded into the machine code, and shouldn't be too important if
you're only programming in assembly. But this is a guide to x86_64 instruction encoding, so soon
we'll talk about the REX prefix. Anyways, in assembly, you refer to
the registers by name. Like, you can do "add rax, rcx" to set rax
equal to rax + rcx. Or you can do "add eax, ecx" to do the same
thing but with the 32 bit subregisters, clearing the higher bits.
But in assembly, the register operands must be the same size. "add rax,
ecx" is invalid and will error.
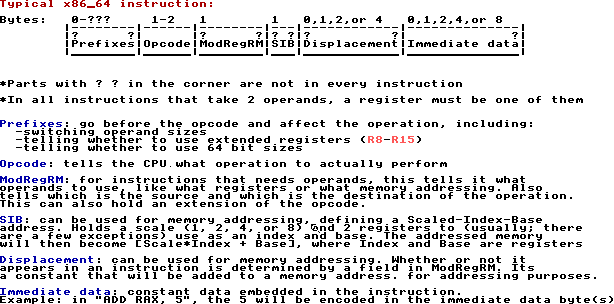
Instructions are composed of, in this order:
Optional prefixes: some, like the address/operand size overrides 66h and 67h, will be put here
implicitly by the assembler, while others, like 'lock', can be declared explicitly in assembly before
the mnemonic. Of course in instruction encoding, all must be done explicitly.
The opcode: this is determined by the menmonic. At a lower level, each assembly
mnemonic may have more than 1 opcode it can become, and the one that gets picked depends
on the types of the operands.
Bytes that specify the operands. Also other bytes. These include the ModR/M byte, the SIB byte, and any immediate values.
Here's a slightly more in-depth diagram:
Remember, each statement in assembly corresponds to 1 machine code instruction. There's traditionally 1 statement
per line, too, and usually anything after a semicolon is a comment and not even considered part of the code. Although
in TempleOS, comments in assembly come after // or in between /* and */. They're green. Comments in all programming
languages are usually either green or gray.
So now that we kinda know all this stuff, how can we encode a simple instruction like "add rax, rcx"? Well that uses
64 bit registers, which would require the REX prefix and complicate it a bit, so lets start with "add eax, ecx", the
32 bit registers. What do we know? The 'add' mnemonic must become an opcode, and the "eax, ecx" register operands
must be encoded in the bytes that come after the opcode. Hmm. But what opcode would such an add become? And what about
the bytes to encode the operands?
Before going any further, you should get a copy of some x86 or x86_64 technical reference. The Intel software
developer manuals are available here and
is what I'll refer to a lot here; some other resources include:
They're all free. Some of them are kinda hard to find your way around at first, though, but once you can
read them, they'll contain pretty much everything you need to know to encode x86 instructions. I like to
use the complete Intel SDM, which you can download here.
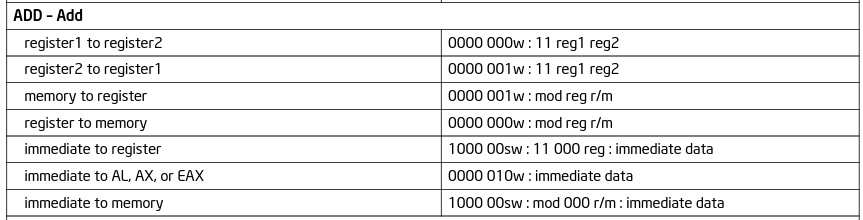
OKAY, so to sort out the opcode part, we're looking for an add opcode that takes 2 32 bit registers as operands.
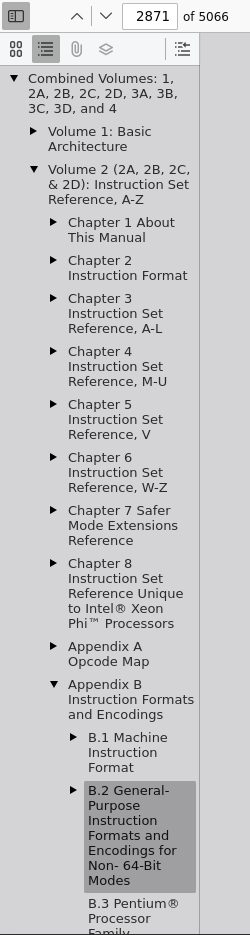
I found that the easiest way to get this stuff is by going to the Intel SDM volume 2, appendix B, and finding the "B.2
general-purpose instruction formats and encodings for non 64-bit modes" table; in the complete manual, this is
on page 2871. Here's its location in the outline of the Firefox browser's PDF viewer:
*Hopefully you can navigate large PDFs. The google chrome PDF viewer is very bad... maybe use firefox instead, also because
google is shit for privacy. Or try some PDF viewer like zathura, or
if you're on Windows, maybe sumatraPDF (version
3.1.2 if on Windows XP). I won't be showing a screenshot of the PDF outline and the current location every time I refer
to the Intel SDM.*
So I really like that B.2 table. Check out the parts for the add mnemonic:
It actually, more or less, gives the full encoding for such an instruction. It's in binary, but there are random letters
and phrases mixed in; these are called fields, and their values will affect the operation. Each colon delineates bytes,
and usually anything with a field will contain 1 byte, so 8 bits. The first group of bits is the opcode (although note that
an opcode may be 2 bytes large, and it may extend into the reg field of the ModR/M byte. But we'll worry about that
when we get to it), but we'll probably wanna know what the w field is, right?
The w field of an opcode tells what size of a register to use. When it's 0, it'll be byte-sized (using the 8-bit
subregisters!). When it's 1, the register size will be either 16, 32, or 64 bits; the selected size will depend on the
prefixes and the default operand size. The default operand size is 32 bits even in 64 bit mode! This information
can be found in Intel SDM volume 2, appendix b, b.1.4.1 (page 2866-2867 in the complete PDF). In our example we wanna
encode, "add eax, ecx", we're using 32 bit registers, so w will be... 1
Now we have our opcode: 00000001 or 00000011. In hex, it would be 01 or 03. We can use either one of these to add
one 32 bit register's value to another. The only difference between them is which reg field is treated as the source
and which one is the destination. This can lead to 2 perfectly valid encodings for the same instruction! Let's just choose
01 as our opcode. (NOTE THAT THESE ARE IN HEX). It means "add register1 to register2". The actual meat of the instruction,
the selection/encoding of the registers, are in the byte after the opcode: "11 reg1 reg2".
We want register 2 to be eax since it's being added to, so register 1 will be ecx. Obviously, then, the reg1 field must be
ecx, and the reg2 field must be eax. But it's all in binary, so how do we specify those registers? Refer to the table
of registers on this page; the code is the 3 digit binary code we use to specify registers! So, reg1 will be 001, and
reg2 will be 000. Plugging those codes in to the instruction, we get:
"add eax, ecx" (add ecx to eax)
add register1 to register2 = 0000000w : 11 reg1 reg2 [FROM TABLE]
w = 1 (meaning not 8 bit operands)
reg1 = 001 (code for ecx)
reg2 = 000 (code for eax)
SO...
00000001 11001000
or, converted to hex...
01 C8
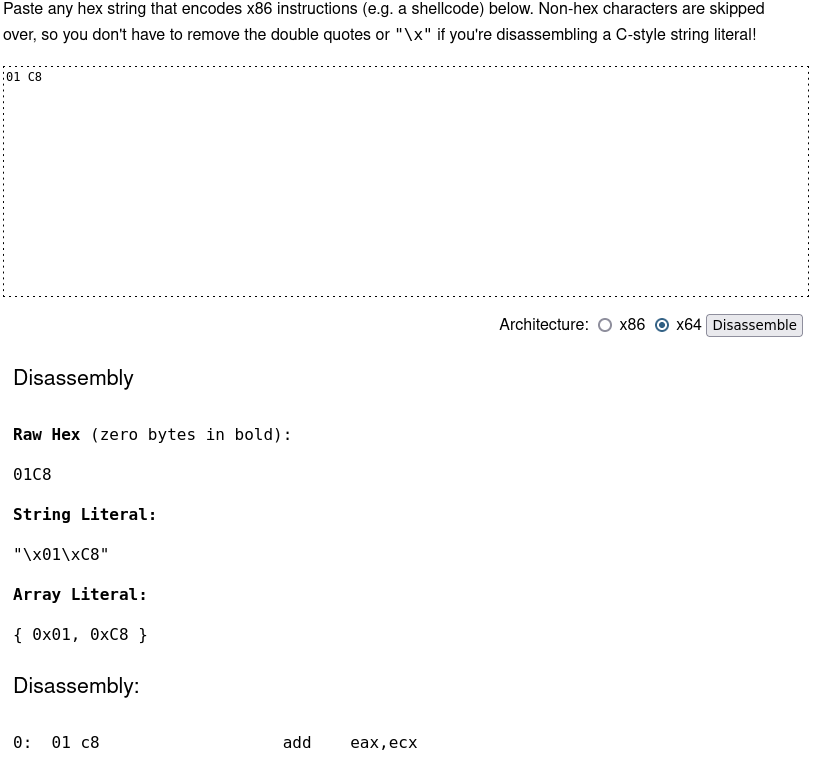
00000001 11001000 is machine code for "add ecx to eax"? How can we check this? You can use a program called an unassembler.
An unassembler (sometimes called a disassembler) does the opposite of an assembler: it turns machine code back into assembly statements. Check out
this site for an online assembler and unassembler. Its unassembler takes
hex input, though, so make sure to convert your binary machine code to it. But we can confirm that our machine code is correct:
That site's assembler will output its assembled code in hex format, too, so you can see how other instructions are encoded.
It's a good tool. There are a few differences between x86 and x64, though. (Remember that x64 is synonynmous with x86_64
and amd64). First of all, x86 is 32 bit, so it won't work with 64 bit registers. Inc or dec mnemonics also might get messed
up. (In x86, many inc/dec opcodes begin with 0100 in binary; but in x86_64, the REX prefix begins with 0100 too, so it
replaces those inc/dec opcodes).
Anyways, you should now notice that it's easy to take that same instruction and switch the reg1 and reg2 fields to make
it act on different registers. We can't yet encode any of the extended registers (R8-R15), or any other sizes, but
EAX, ECX, EDX, EBX, ESP, EBP, ESI, and EDI are fair game. So mess around with that and see what other add reg32 reg32
instructions you can make. "add ecx, edx"? "add ebp, edi"? "add esp, esp"?
But there will come a time when people want to use the 16 bit or 8 bit subregisters instead of only the 32 bit ones.
Up till now, the default operand size has been 32 bits, but how can we encode 16 bit or 8 bit subregisters? The 16 bit
subregisters are easy; there's a prefix called the "operand size override" you can put before the opcode, and it'll switch
between 16 bit and 32 bit operand sizes. It's value is 66 (IN HEX), or 01100110 in binary. So, to make our previous 01 C8
(add eax, ecx) become 16 bit, just add 66 before it, and boom, it's now: "add ax, cx". Not too bad.
add eax, ecx = 01 C8
add ax, cx = 66 01 C8
But hmm, what about 8 bit subregisters? Well, remember the w field in some opcodes, including the add opcodes? Simply
set that to 0. No prefixes needed. So now our opcode for 'add reg1 to reg2' is 00000000. Note that some registers
have funky codes for 8 bit sizes. Having a code of 110 when w=0 will NOT encode SIL but rather DH (high 8 bits of DX).
Encoding SIL and others needs a REX prefix (will go over later). Make sure to have the register codes handy
add eax, ecx = 01 C8
add al, cl = 00 C8
So, to summarize:
To encode 64 bit or extended (R8-R15) registers: use REX prefix, 4_h
To encode 32 bit registers: nothing special needed; even in 64 bit mode, 32 bit registers are default.
To encode 16 bit registers: use the operand size override prefix, 66h
To encode 8 bit registers: set w field of opcode to 0
The top one was included for completeness. The REX prefix, including using the extended and/or 64 bit registers, will be covered now.
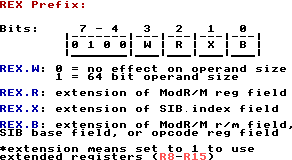
The REX prefix is a byte new/exclusive to x86_64 and has the form 0100WRXB, where W, R, X, and B are 0 or 1.
Information on it can be found at the Intel SDM volume 2, chapter 2, 2.2.1: REX Prefixes (page 532 in the complete SDM).
So, to use 64 bit registers in an instruction, all we have to do is add the REX prefix to that instruction and have its
W field be set to 1. The REX prefix must come immediately before the opcode. But as long as we do that, it's not that bad:
add eax, ecx = 01 C8
add rax, rcx = 48 01 C8
Because 0100 is fixed in the REX prefix, and 0100 in decimal is 4, all REX prefixes written in hex will begin with 4.
The 3 other fields in the REX prefix specify whether to use extended registers. But before we go into that, we should
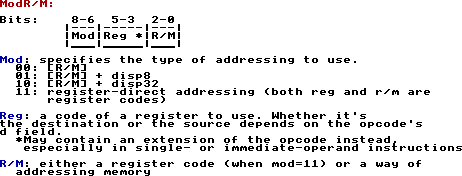
look at the ModR/M byte, because we've actually been using it this whole time!
Sometimes I call the ModR/M byte the "ModRegR/M byte". I don't know why. But assume
I mean ModR/M.
In our instruction encoding for 'add' given to us by the table, "0000000w : 11 reg1 reg2", the first byte is the opcode,
but the second is actually the modr/m byte. In it, mod is 11 (meaning register-direct addressing), reg1 is the reg field,
and reg2 is the r/m field. The modr/m byte is used to specify memory addressing; when mod=11, though, it's just plain
register to register. But now that we know that reg1 is reg and reg2 is r/m in our example, we can set REX.R and/or REX.B
to 1 to extend them respectively. After all, REX.R, REX.X, and REX.B are extensions of the register code.
:::::::::::::::REX opcode modr/m byte
| | |
add rax, rcx = 01001000 00000001 11001000
RAX is encoded in the reg field of ModR/M, so to extend it to R8 (which has otherwise the same 000 code), set REX.R to 1
RCX is encoded in the R/M field of ModR/M, so to extend it to R9 (which has otherwise the same 001 code), set REX.B to 1
add r8, r9 = 01001101 00000001 11001000
In hex: 4D 01 C8
One thing to note is that if REX.W is 0, then the operands aren't 64 bit sized. By making it 0 but still extending the registers,
you can access the subregisters of R8-R15 as though they're any other register: this is how to encode
R8D-R15D, R8W-R15W, and R8B-R15B. Additionally, if REX is 01000000 (40h), then it's present,
but doesn't really do anything. However, since SPL, BPL, SIL, and DIL can only be encoded when REX
is present, they can now be encoded rather than AH, CH, DH, or BH respectively (when w=0 in the opcode, of course), despite having the same code.
Addressing
The following are all general valid forms of memory addressing that can be done in an instruction:
[reg]: ModRM with Mod=00 and reg in RM field
[reg + disp8]: ModRM with Mod=01 and reg in RM field
[reg + disp32]: ModRM with Mod=10 and reg in RM field
[disp32] (constant address in x86, RIP-relative address in x64):
ModRM with Mod=00 and RM=101
When RM=100:
-----------
[reg + reg2]: SIB byte with Scale=00, Index=reg, Base=reg2 (or equivalent)
[reg * (1|2|4|8) + reg2]: SIB byte with Scale != 00, Index=reg, Base=reg2
[reg * (1|2|4|8) + reg2 + disp8]: ModRM with Mod=01, SIB byte
[reg * (1|2|4|8) + reg2 + disp32]: ModRM with Mod=10, SIB byte
[disp32] (both x86 and x64): ModRM with Mod=00, SIB byte with Index=100, Base=101
Reg and reg2 generally refer to a register, but a few registers act as "escapes" and cannot be used
in certain addresses in certain ways. The only registers/codes used in this way in this context
are: 100 (RSP) and 101 (RBP)
Can't do much without addressing. Many X86/X64 instructions can take a memory operand in place of a register operand; this is true wherever there's a 2-operand
instruction that uses a ModRM byte, such as ADD (ex: add register to value in memory) or MOV (move register value to/from memory). The Mod field of ModRM is what specifies the type of memory addressing to be used. When it's 11, it's register-direct,
meaning it doesn't address memory and only deals with the contents of the registers, but with it's 00, 01, or 10, it's now what's called register-indirect.
As an example, check out these ModRM bytes and "operand parts" they correspond to, assuming that the opcode is for a 2 operand instruction (such as "add reg,
r/m") and the opcode's d bit is 1 (making Reg the destination and R/M the source):
Having a ModRM byte with Mod=00 is the simplest way to address memory by using (or in conjunction with) ModRM. When Mod=00 and RM has a register code (that
isn't 100 or 101, which are used for more advanced addressing), then the value that gets passed as an operand (if it's the source) or operated on (if it's the destination)
is the value stored at the register-th byte of ram. Look at this instruction, the encoding for "add ebx, [eax]":
This will add to EBX the value pointed at by EAX. In other words, the 32-bit number at the EAX-th byte of RAM will be added to EBX. While to some this may seem too low-level to
be useful at all ("it's too tricky having to manually manipulate bytes of RAM when my computer has billions of them!") remember that it's pretty much just a pointer from C!
A pointer in C is just an address of something stored in memory. If a value in a register is the address of something in memory, then you could call it a 'pointer', and doing
this type of register-indirect addressing could be considered dereferencing that pointer.
So now this seems pretty okay, right? With the exception of RSP/R12 (RM=100) and RBP/R13 (RM=101), now memory can be accessed or manipulated by putting the address inside of
a register and using register-indirect addressing in this way. It's not too difficult either. But... there are more ways to address memory in x86/x64, and using these
modes involves setting RM to either 100 or 101
Mod=00 RM=101
When Mod=00 and RM=101 in a ModRM byte, it means that the effective address will be just a [disp32] that follows. Disp32 is a 4-byte-long displacement that comes after the ModRM byte (refer to
this diagram for the layout of a full instruction and where this displacement goes in it) and represents a number that's the address. What this
means is that the memory address is, in a way, baked directly into the instruction instead of being contained in a register. This can be used when the memory address is a
constant, like when there's a string included in the program and an instruction wants to use the address of that string for
any reason, like to print it. You could always just put the address into a register and then use the addressing mode
above, of course, but doing it this way encodes it in a single instruction instead of 4+ (pushing register, loading address into register,
actual instruction, popping register).
Here's an example of this kind of addressing in action; it's an assembly function that stores 'H ' in memory, loads it into
RAX (from its address), and prints it. The encoding of the MOV instruction will use this addressing:
But there's an additional complication in how exactly that displacement is translated to an actual memory address... and
how the bytes that make it up are encoded. In 32-bit x86, the displacement will represent a memory address; if the displacement is
123, then the memory it addresses will be the 123th byte of RAM. However, x64 introduced what's called RIP-relative addressing, which
is where the RIP register gets added to the displacement to get the memory address. To this end, if you'd like to assemble an
instruction like in that example above (ex. assemble "MOV RAX, [H]"), you'll need to know a few things to assemble the instruction
with a [disp32] so that it'll address the memory you actually want (the "H"):
the address of the desired memory
the address of the instruction
the size of the instruction
So in x64, the Mod=00 RM=101 mode of addressing denotes that a [disp32] follows, and the actual address it represents is [RIP + disp32].
RIP is a special register that always points at the address of the next instruction to be executed.
If 'thing' is something in memory (like a string) known at compile time,
then it can be addressed with Mod=00 and RM=101 in the following ways:
32-bit x86:
disp32 = address of thing
64-bit x86 (x64) using RIP-relative addressing:
disp32 = address of thing - instruction's address - instruction's size
It's still possible, however, using SIB addressing (explained next) with base=101 and index=100 to address memory
through a disp32 without using RIP-relative addressing.
Relevant Intel SDM sections (volume 2) include:
2.1.5: Addressing-Mode Encoding of ModR/M and SIB Bytes
2.2.1.6: RIP-Relative Addressing
It should also be noted that in the formula given above to find the displacement needed to address a specific thing in memory
with RIP-relative addressing, the addresses of the thing and of the instruction are really only needed to find what to
add to RIP to get there; you don't need to know the addresses of the instruction and the thing after the program is loaded
into memory, only the distance (in bytes) between the thing and the instruction (as well as the size of the instruction).
It's pretty easy to go "hey, when Mod=00 and RM=101, then the only address used is a 32-bit displacement", but explaining how to use that
in practice is a bit harder, especially with this difference between 32-bit and 64-bit operation. But oh well.
SIB Addressing (RM=100)
When RM=100 in the ModRM byte, then what immediately follows is a SIB Byte. SIB is short for "scale-index-base" and is used
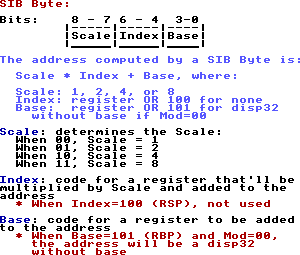
for a more advanced memory addressing mode. The SIB byte is a byte long and consists of 3 fields:
A SIB byte should only be present in an instruction when RM=100 in a ModRM byte. It allows you to encode memory addresses such as
"[rax*4 + rdx]" directly into the instruction! But what's the advantage of that when you can just multiply RAX by 4, add RDX to RAX,
then use RAX by itself to address memory as in the register-indirect addressing from before? Well, probably mostly just code size:
the SIB byte only adds 1 byte to the instruction, while addressing using the latter method would require a bunch more instructions.
To use a SIB byte, figure out the registers and scale you want in the following formula: Index*Scale + Base, where Index and Base
are both registers, and Scale is 1, 2, 4, or 8. If you don't want an Index, set it equal to 100 (RSP) and it won't be used. This
means that RSP can't be used as an index, however. In the context of SIB bytes, the phrase "scaled index" refers to Scale*Index.
If Base=100 (RBP), then the following address modes apply:
Mod=00: [scaled index] + disp32 You can use this with Index=100=none to address memory with a constant disp32 in 64-bit mode if needed
Mod=01: [scaled index] + disp8 + [RBP]
Mod=10: [scaled index] + disp32 + [RBP]
Now let's encode some instructions that use memory addresses trickier than [reg]!
add rcx, [rax + rdx]
0x48 0x03 0x0C 0x02
01001000 00000011 00001100ModR/M byte; value: 0xC Mod = 00 Reg = 001 R/M = 100 00000010
REX opcode ModRegRM SIB
1. In this instruction, we're adding to a 64-bit register, so we need a REX prefix
where REX.W=1, to denote 64-bit operand size.
2. Next comes the opcode for ADD. Since a memory address is being added TO a register
(and memory addresses can only be in the RM field of ModRM),
the d bit (2nd bit; bit 1) needs to be set to 1 to denote that RM->reg
3. Then there's the ModRM byte. Mod=00 since memory needs to be addressed,
but no constant displacement is needed (like disp8 with Mod=01 or disp32
with Mod=11). 001 is put in the Reg field since that's RCX. 100 is put in
the RM field since that denotes that a SIB byte follows...
4. Next is the SIB byte. Scale is 00 since no scale is needed. Index is 000 for RAX
and Base is 010 for RDX. So the computed address will be [RAX + RDX]. And you're done!!
* Note that the Index and Base fields in the SIB byte can be swapped.
add [rbx*4 + rdx], rsi
0x48 0x01 0x34 0x9A
01001000 0000001 00110100ModR/M byte; value: 0x34 Mod = 00 Reg = 110 R/M = 100 10011010
The process for this instruction is the same except the registers are switched around,
the d bit in the opcode is set to 0 (since now, reg is being added TO a memory location),
and scale is set to 10 for the *4.
If the Mod field in the ModRM byte is 01 or 10, it denotes a constant displacement (disp8 or disp32 respectively) that gets added
to the address. This displacement is encoded into the instruction in the 'displacement' part of the instruction, and can be there
IN ADDITION TO a SIB byte address. This allows for a full addressing scheme of [reg*scale + reg2 + displacement],
for example: [rax*8 + rcx + 3200].
 -NO GLOWIES ALLOWED BEYOND THIS POINT-
-NO GLOWIES ALLOWED BEYOND THIS POINT-

 LEARN X86/X64 ASSEMBLY NOW
LEARN X86/X64 ASSEMBLY NOW Links
Links
 Milk/Yogurt Ratings
Milk/Yogurt Ratings Rating most other foods I eat
Rating most other foods I eat Chat room
Chat room Miscellaneous
Miscellaneous